
Hi everyone, today I’m going to talk about how the Steering Committee has been playtesting cards at the end of season 3 and going into Season 4 (more on that next week!). This is based on my own personal experience with the committee, so it’s important to keep in mind that all of this is a reflection of what has been going on since I joined in late February, and I don’t really know how things were done for seasons 1 and 2 and leading up to the release of season 3.

When I was first brought onto the committee, our main focus at the time was getting the cards in Season 3 into fighting shape. At first we made small changes leading up to the Vassal Regional at the end of March so as not to be too disruptive, but then we decided that more drastic changes were needed. You can read about a lot of this process in my Designer Diaries articles on the Season 3.2 updates.
We realized we needed to be a bit more aggressive with our card designs in terms of how powerful they were, but in order to make sure our designs were strong but not completely “broken”, we needed to actually put those cards into action and see what they could do on the table. It’s very difficult, especially in a game like Imperial Assault, to get a good feel of how powerful a card is going to be just by looking at it and running “head sims”, or mental simulations of how that card will play out, because games of Imperial Assault have a lot of moving pieces and variables that impact each game and change from game to game and between different lists.

It started with Derek and I playtesting our Yoda designs on Vassal with the idea that Yoda was a special figure that needed extra attention and care to get it right for the 3.2 update. I think we realized how valuable even 1 or 2 playtest games were for identifying and correcting problems for a brand-new card. Abilities that we thought looked okay on paper quickly became obvious within just a turn or two as being either brokenly powerful or completely useless, and we were able to make adjustments that were much more grounded in actual gameplay experience. I think the previous mindset had been that playtesting was something that we couldn’t do effectively without involving the community, which may have been the case when there were a lot fewer members on the committee, but I realized that this was something that the committee could and should do internally for all of our new designs to help us get our cards closer to the final product before they go out to the public for open playtesting, especially now that the committee had expanded its numbers.
Before I played Imperial Assault, I was a Magic: the Gathering and X-Wing tournament player, and to me, this kind of small-scale small-group playtesting felt a lot like the kind of playtesting I used to do with my friends to prepare for a Magic or X-Wing tournament, and I had read a lot of great articles from the past 10 years about how to maximize playtesting data coming out of a small group of players playing a relatively small number of games. I had also read a lot of articles from Magic’s lead designer about how they conduct their in-house playtesting and what kind of feedback they look for from in-house playtesters. To help promote more playtesting of new cards within the Steering Committee as a regular part of our design process, I put together a guide on qualitative playtesting based on those articles and shared it with the committee, along with links to the original articles for reference. You can check out a public version of that document with committee comments removed here: https://docs.google.com/document/d/1Rj82BxJZITI5lzc-L6RtAW3o5b7rSeGCyjPOMhbaWsQ/edit
Now the IACP Steering Committee has a dedicated channel on our Committee Slack (which is separate from the Zions Finest Slack) for setting up playtest games, similar to the #lfgvassal channel on the Zions Finest slack, and committee members who have time are eager to playtest their designs as well as the designs of other members. I would say that for the 6 weeks we’ve had about 1-3 playtest games played each week for Season 4 cards, and most of the cards in Season 4 have been playtested at least twice, if not 3 or 4 times. That might sound low, but when you’re dealing with cards that are very very raw design-wise, every playtest yields a ton of information about how that card plays on the table and things that need to be fixed or adjusted. Most of the cards we’ve designed for season 4 have had some adjustments made after a playtest or two, and we always make sure to do another playtest after a card has been adjusted.
When we do our playtest games, the vast majority of the time they are happening in Vassal, though some committee members also playtest with friends and family at home. If you ever see any of the committee members in a locked room on Vassal, we’re probably playtesting content from the new season. Because we can’t easily load custom content into the vassal module ourselves, we have to reference the playtest cards externally, and use proxy cards in Vassal to represent them, usually cards from a different faction with the same deployment cost and maybe traits, and we change the name on the card and on the figure to the name of the card we’re testing. Even though Tabletop Simulator does make it super easy to load in custom content, it just hasn’t caught on with the committee, mostly just because of how much faster games are on Vassal when you’re familiar with the system.
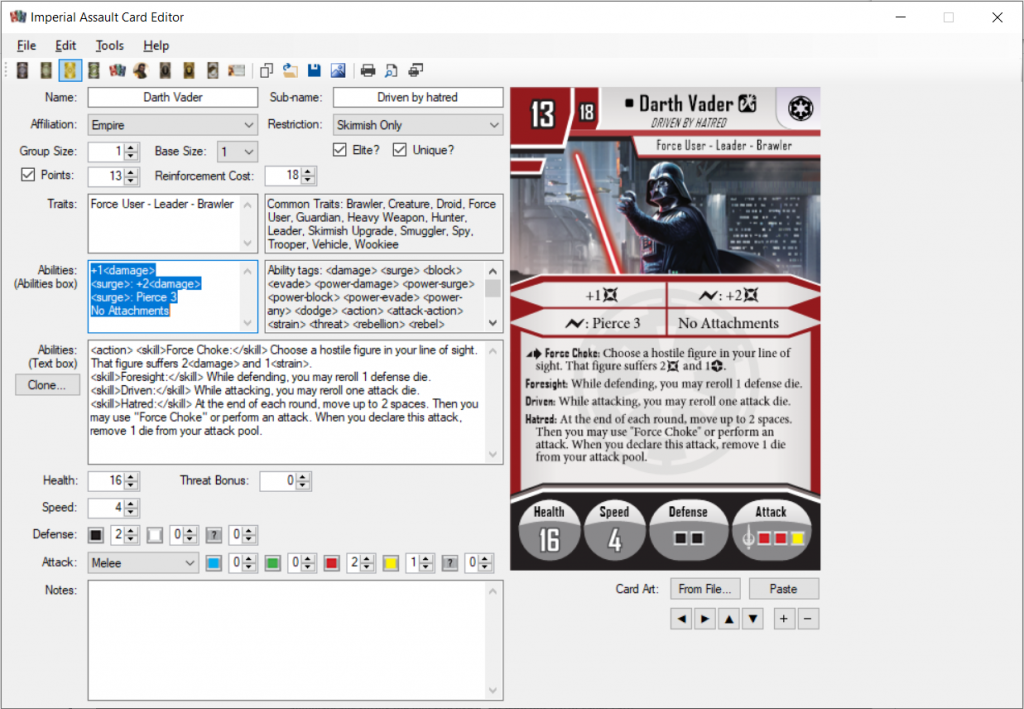
We use Bitterman’s Imperial Assault Tools Suite to generate our playtest card images, and in the early days of Season 4 testing we would PM the card images to each other in the Committee Slack for easy reference before a game, but as we narrowed down which cards were going to be featured in Season 4, we created a shared Google Drive folder and work together to keep it updated with the latest versions of all the new cards for easy reference. This also made it a lot easier to test other people’s designs without having to dig through old Slack threads and guess which of the many many different versions of the same card was the most current version.
We try to do our playtest games on maps that we know are balanced and are familiar to us. This helps us to be less distracted with playing the map and focus more on the figures we’re testing. For me, Renovation on Endor Defense Station and To Your Stations on ISB Headquarters are favorites of mine, since they are fairly balanced mid-sized maps with simple layouts, unlocked doors on each side, and feature the most common objective types in IA which are pick-up and deliver and hold-and-control. Though it would be great to be able to play every card on every map and mission, that’s just not an efficient use of our limited playtesting time, so I like to focus mainly on the missions that offer a more generalized skirmish experience. We do sometimes throw in new maps that we are considering for rotation every now and then.
For listbuilding, we all kind of take responsibility for building our own lists to test, but for me personally, I try to find a balance between a list that’s strong and a list that has multiple new cards in it so I can get multiple cards tested in one game. I also try to always include 1 or 2 high tier figures in my lists that are at a similar points cost so that I can compare the figures I’m testing and my opponent is testing to what we already know is strong but not broken, and I try not to go too overboard with new cards in my list. I also try to build my lists to keep the figures that I’m testing alive, and I play more defensively with those figures as well. It’s not much of a test if the figure you’re testing with dies before it gets to do anything. Chewbacca often makes it into my testing lists with Rebels since he’s so punishing if you kill anything other than Chewbacca first. Sabine and Onar also tend to make it into my testing lists, since they are some of the strongest mid-cost figures and a lot of the figures we are developing for Season 4 are in the 6-8 point cost range.
After we finish a playtest game, both players go back to the Committee slack channel and post their thoughts from the game either in the playtesting channel or in the individual threads for the cards themselves. We share our thoughts on how the cards performed in the specific situation and matchup, and what changes we might suggest, or if we thought no changes were needed.
So what are we looking for when we playtest these cards? For me, there are two main things I’m testing for in a playtest. Balance and Fun.
Playtesting for Balance
Gamers are notoriously bad at judging the power level of a card after just one game, and that includes Committee members. People are quick to label things as broken or weak before they’ve actually figured out how they work or how to play against them. That is why we have our public playtest leagues to help us figure that out over many games played by the community. But it’s usually not difficult to tell if a card is utterly broken after 1 or 2 playtests, but it can be surprisingly tricky by just looking at the card without playing it. When we actually put the card into action, it’s easier to tell if it’s doing something that makes it obviously too powerful for its point cost. Usually this happens when an ability is too spammable in the same round, or when we don’t properly account for force multipliers on a card or from support figures in a list. We also try to identify when it feels like a card isn’t pulling its weight, is dying too easily or is punching below its points weight class compared to other similar figures with the same resources.

I’ve also personally noticed a tendency to grade an attack’s accuracy based on its minimum range (the lowest range that can be rolled on the dice) rather than it’s average, median and maximum range, because as players we are often looking for attacks that are “range safe”, that we know are not going to miss, but this causes trouble when we make an attack’s minimum accuracy too high with accuracy bonuses and that pushes up the average and max accuracy of the attack, especially when you start adding in things like Focus and rerolls and external accuracy buffs from things like Hera. Suddenly a figure that we intended to be good at attacking at range 5 is able to make attacks at range 10. Instead of giving a figure with a Blue/Green/Yellow attack pool an innate +2 Accuracy bonus or +2 accuracy surge to allow it to attack at range 5, we are okay with it just being 80% to hit without the accuracy bonus and accepting that things like Focus and accuracy bonuses are available as resources that the player can expend if they want to have more reliable accuracy.
The ability to tell from one or two games whether a card is over or underperforming is all based on subjective observation based on our experience as competitive players. We have played so many competitive games in tournaments with the best figures in the game, we have developed a good sense for how much damage a figure should be able to deal or take each round based on its points cost, or how much a support figure is contributing to a game with its abilities. We make sure to pay extra attention to how much non-attack abilities are contributing to the game. What we aren’t doing is tallying up wins and losses for the cards. At this point in development, cards are being freely adjusted and can change rapidly from one game to the next, which makes tracking results for different versions of a card less useful. More importantly, a card could be totally overpowered and still lose a game based on a host of other circumstances, and similarly for a game won with a card that is underpowered. The outcome of a game is decided by much more than just the power level of a single figure, dice variance and player skill are also big factors (sometimes I can only playtest right after work and my game’s not at its sharpest), so while we do sometimes take note of a game’s outcome when it’s relevant, it’s certainly not the most important metric for this level of playtesting.
Playtesting for Fun…ness
Equally as important as balance is whether a card is fun. It turns out that a card can be perfectly balanced, and not be any fun to play with or against. People often equate balanced with fun, since a game can become very unfun when it’s unbalanced, but being balanced is not enough to make a game fun. Since fun can be a very idiosyncratic word for a lot of people, meaning multiple things, I’ll be more specific and say that we’re making sure that the cards are creating new and interesting play patterns that lead to fun and interesting gameplay, and in a way that synergizes with things that are already in the game without breaking them. Does the card create new and interesting problems for players and their opponent’s to solve in multiple ways? Does the card create meaningful choices for players to make? I have found playtesting is really important for figuring this out as well. Sometimes we’ll come up with a card that seems really interesting to look at and read in a vacuum, but then in gameplay it doesn’t play out as fun or interesting as it was to read. And equally important, does the card create lose-lose scenarios for players or create too many non-choices, aka negative play experiences? Even cards that are not that strong can have this problem, and we want to avoid boring gameplay where there is one optimal play pattern that is too easy and too safe.
Does the card feel too similar to an existing card without adding anything new to the game? A card might be perfectly balanced, but if it’s not offering new experiences or new play patterns from what is already in the game, we’re not really accomplishing anything. Another thing to think about is that when you start adding more things into the game that are already there, you might be creating an imbalance by removing the uniqueness of the original cards and making them too spammable. This has happened to FFG multiple times with things like the Royal Guards, Ugnaught Tinkerers, and Riot Troopers, and to IACP with Stun in Season 3, and in Season 4 when we tried to make a new Trooper unit that ended up being too similar to elite Stormtroopers, it turns out that being able to run 3 groups of elite Stormtroopers in a list is just too much for a lot of lists to deal with in terms of attrition. But we still keep existing cards in our minds, especially underplayed cards, and we like to tailor our designs when we can so that they interact with existing cards to create new avenues for play.
I think for some of us more competitive players, this is the harder of the two things that we have to pay attention to. When we play games competitively for a long time, our senses get tuned to finding the most powerful and broken things as well as weeding out the weak stuff, because that’s what we need to do in order to figure out the best list to take to a tournament. But as competitive players, the competition is intrinsically fun to us, and so we’re rarely asking ourselves “am I having fun right now from this gameplay?” But for players that are less focused on competition, and to create the motivation to even want to play the game competitively, there needs to be something else that the cards are adding to the game other than just another way to deal damage to your opponent’s figures faster than they deal damage back to you, to keep the game fresh and interesting.
Well, that ended up being a lot longer than I thought it would be, but I hope you enjoyed this deeper dive into how the Steering Committee is handling internal playtesting for Season 4. We’ve got some big announcements coming up regarding Season 4, the playtesting league, and organized play, so stay tuned!